주의할 점! byte, short형은 컴파일 시 JVM에 의해 int형으로 바뀐다. 즉, 위의 byte 변수도 실행 시 int형으로 바뀐다는 것이다. 해당 오류로 알 수 있는데, byte형에 byte형을 넣어서 정상 동작할 것 같지만 컴파일 시 byte x가 int형으로 바뀌기 때문에 byte에 int를 넣는 꼴이 된다. 따라서 빨간 줄이 그어진 것이다.
해당 문제를 해결하기 위해선 아래와 같이 byte형으로 형변환을 하거나 int형으로 받아야 한다.
논리 부정 연산자(!)
논리 부정 연산자는 boolean형에만 사용할 수 있는 연산자이다.
true는 false, false는 true로 바꾸는 동작을 한다.
ture였던 x에 논리 부정 연산을 했을 때 false가 됨을 알 수 있다.
사칙 연산자(+, -, *,/)
사칙 연산자 들어가기 전!
이항 연산자부터는 피연산자의 자료형을 중요하게 봐야 한다. 그 이유는, 연산을 수행하기 전
1. 크기가 4byte 이하인 자료형은 int형으로 변환하기 때문이다.(byte, char, short) 즉, byte + byte는 int + int로 변환한 후 연산을 수행해 int형 결과가 나온다.
2. 피연산자의 타입을 일치시키기 때문이다. 이때, 더 작은 크기의 타입이 큰 크기의 타입으로 바뀐다. 예를 들어 int + long는 long + long로 변환되어 long형 결과가 나온다. (int + float은 float + float, float + double은 double + double로 변한다.)
예로, 위 코드는 byte + byte는 int형인데, byte 변수에 담으려고 해서 오류가 발생한 것이다. 그럼 byte로 형변환을 해보자.
또 오류가 발생했다. 그 이유는 연산자 우선순위에 의해 +연산보다 (byte) 연산이 먼저 수행되기 때문이다. 따라서 아래와 같이 괄호로 묶어야 한다.
위의 변환 때문에 Java의 사칙 연산은 모르고 사용했다가 이상한 값이 나올 가능성이 크다.
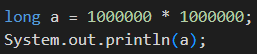
예를 들어
a * b는 1000000000000이다. 이 값은 long이 수용할 수 있는 값이기 때문에 올바르게 나올 것 같지만 결과는 아래와 같다.
오버플로우가 발생한 것인데, 그 이유는 int * int의 결과는 int이기 때문이다.
즉, a * b의 결과가 int형으로 나온 후 long에 담긴 것이다.
이를 해결하기 위해선 아래처럼 아무 변수나 long형으로 바꾸면 된다.
int와 long의 연산은 long으로 결과가 나오기 때문이다.
이와 비슷한 예로
해당 연산의 결과도 아래와 같이 나온다.
위의 예와 비슷한데, int * int의 결과가 int로 나왔고, 그 값이 long a에 담긴 것이기 때문이다.
해결하려면 아래처럼 L을 붙여 long형임을 알리면 된다.
나머지 연산자(%)
나머지 연산자는 나머지를 반환하며 boolean형 이외의 자료형에 사용할 수 있다.
아래 연산은 정수일 때로 5를 3으로 나눴기에 2가 나왔음을 알 수 있다.
실수일 때에도 정상 동작한다.
나머지 연산자는 음수의 영향을 받는데, 아래와 같이 연산을 수행하면
이러한 결과가 나온다.
즉, 나머지 연산자는 왼쪽 피연산자의 부호에만 영향을 받는다.
쉬프트 연산자(>>, <<, >>>)
쉬프트 연산자는 정수형 변수에만 사용할 수 있다.
이 연산자는 변수의 비트를 왼쪽 혹은 오른쪽으로 이동시키는 연산을 한다.
예를 들어 >> 연산자의 경우 오른쪽으로 이동시킨다.
아래와 같이 4 >> 1은 오른쪽으로 1번 이동시킨다는 것으로 결과는 2가 나온다.
비트의 이동을 보면 아래 그림과 같다.
가장 오른쪽에 있던 비트는 사라진다. 따라서 만약 4 >> 3을 한다면 결과는 0이 나온다.
반면 << 연산자는 왼쪽으로 이동시킨다.
아래와 같이 4 << 1은 왼쪽으로 1번 이동시킨다는 것으로 결과는 8이 나온다.
비트의 이동을 보면 아래 그림과 같다.
피연산자가 양수일 땐 큰 단순히 옮기기만 하며, 빈자리는 0으로 채운다.
하지만 음수일 땐 오른쪽으로 이동할 때 다르게 동작한다.
먼저 아래와 같이 왼쪽으로 옮기는 -4 << 1을 실행하면 -8이 나오는데,
아래와 같이 동작하기 때문이다.
만약, -4 >> 1이라면 결과는 -2이다.
이것의 비트 이동을 보면 아래와 같다.
다를 것이 없어 보이지만 음수임을 감안해 MSB가 0이 아닌 1로 채워진다. 그래야 계속 음수이기 때문이다.
계속 1로 채워지기 때문에 음수를 아무리 오른쪽 쉬프트 연산을 해도 결국 결과는 -1이다.
아래와 같이 모든 비트가 1로 채워지기 때문이다.
하지만 >>>연산은 다른데, 음수일 경우에도 MSB를 0으로 채운다.
따라서 결과는 아래와 같이 양수가 나온다.
int형의 최댓값이 2147483647 임을 통해 MSB와 LSB를 제외한 모든 비트가 1로 채워졌음을 알 수 있다.
만약 아래와 같이 연산을 수행하면 int형 최댓값이 나온다. MSB를 제외한 모든 비트가 1이기 때문이다.
쉬프트 연산을 정리하자면
<< 연산은 2의 x제곱만큼 곱한 것이며,
>> 연산은 2의 x제곱만큼 나눈 것이다.
쉬프트 연산은 곱셈보다 빠르다. 즉, 8 / 4보다 8 >>2가 더 빠르다는 것이다. 하지만 이는 가독성이 떨어지므로 *, / 를 사용하는 것을 권장한다.
대소 비교 연산자(>, <, >=, <=)
boolean, 참조형을 제외한 기본 자료형에 사용할 수 있다.
두 피연산자의 크고 작음을 비교해 true, false를 반환한다. 따라서 if문, while문에 주로 사용한다.
등가 비교 연산자(==, !=)
대소 비교 연산자와 같이 true, false를 반환한다. 차이점은 모든 자료형에 사용할 수 있다는 것이다.
아래 코드에서 빨간 줄이 없는 것을 볼 수 있다.
(노란 줄은 동일한 표현, 없어도 되는 코드라는 의미)
단, 참조형과 기본형은 자료형을 통일할 수 없기 때문에 동시에 사용할 수 없다.
논리 연산자(&&, ||)
논리 연산자는 true, false만 피연산자로 받는다.
&&는 피연산자가 둘 다 true여야 true를, ||는 둘 중 하나만 true면 true를 반환한다.
해당 연산자들은 표로 정리하면 확실히 알 수 있다.
&&는 둘 중 하나가 false면 false, ||는 둘 중 하나가 true면 true이다.
따라서 컴퓨터는 해당 연산을 할 때 앞 피연산자가 무엇인가에 따라 뒤 피연산자는 계산하지 않는다.
예를 들어 (5 > 3) || (4 > 2) 연산을 할 때
5 > 3이 ture이므로 4 > 2의 결과에 상관없이 전체 결과는 true이다.
또, (5 < 3) && (4 < 2) 연산을 할 때
5 < 3이 false이므로 4 < 2의 결과에 상관없이 전체 결과는 false이다.
이런 경우, 뒤의 연산은 수행하지 않는다.
이것을 Short Circuit Rule이라고 한다.
따라서 ||일 땐 true일 가능성이 높은 것을, &&일 땐 false일 가능성이 높은 것을 앞에 배치한다면
조금이나마 속도를 높일 수 있다.
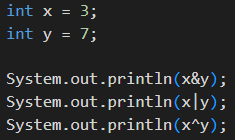
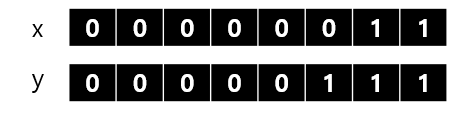
비트 연산자(&, |, ^)
비트 연산자는 두 피연산자의 비트를 대상으로 하는 연산으로, double, float을 제외한 기본형에 사용할 수 있다.